
In the last post, we learnt the basics of Core Erlang, the intermediate language used by the Erlang compiler. In this part, we will explain how to write Erlang programs that transform Core Erlang programs.
Core Erlang Program Transformation
In general, it is more convenient to perform source-to-source transformation in Core Erlang than carrying out this task in Erlang (mainly, if our goal is to generate BEAM bytecode). This is due, in part, to the simplicity of the Core Erlang language.
But, it can become an arduous task at certain times, and the scarce and outdated documentation available does not make it better. Moreover, it is quite difficult to find examples of how to write code for this. The first time working on Core Erlang program transformation, I spent most of the time browsing code on GitHub and developing code by trial and error.
Abstract Syntax Trees
As it is common in programming languages, a Core Erlang program can be represented with an Abstract Syntax Tree (AST for short). The nodes in this tree represent the constructs that occur in the source code. In our context, the terms AST and forms are interchangeable.
For example, the AST that represents the sum_tuple module is a module
declaration (root node) with two function definitions: main/2 and sum_tup/1.
A function definition consists of a pair {Name, Body} where Name is the
name/arity of a function (e.g., sum_tup/1), and Body is the body of the
function (e.g., fun (_@c0) -> case _@c0 of ... end).
module 'sum_tuple' ['main'/2,
'sum_tup'/1]
attributes []
'main'/2 =
fun (_@c1,_@c0) ->
let <Tup> = {_@c1,_@c0}
in apply 'sum_tup'/1
(Tup)
'sum_tup'/1 =
fun (_@c0) ->
case _@c0 of
<{X,Y}> when 'true' ->
call 'erlang':'+'
(X, Y)
<_@c1> when 'true' ->
primop 'match_fail'
({'function_clause',_@c1})
end
Now, let us focus on the main/2 function, that you can find represented as an
AST in the above diagram.
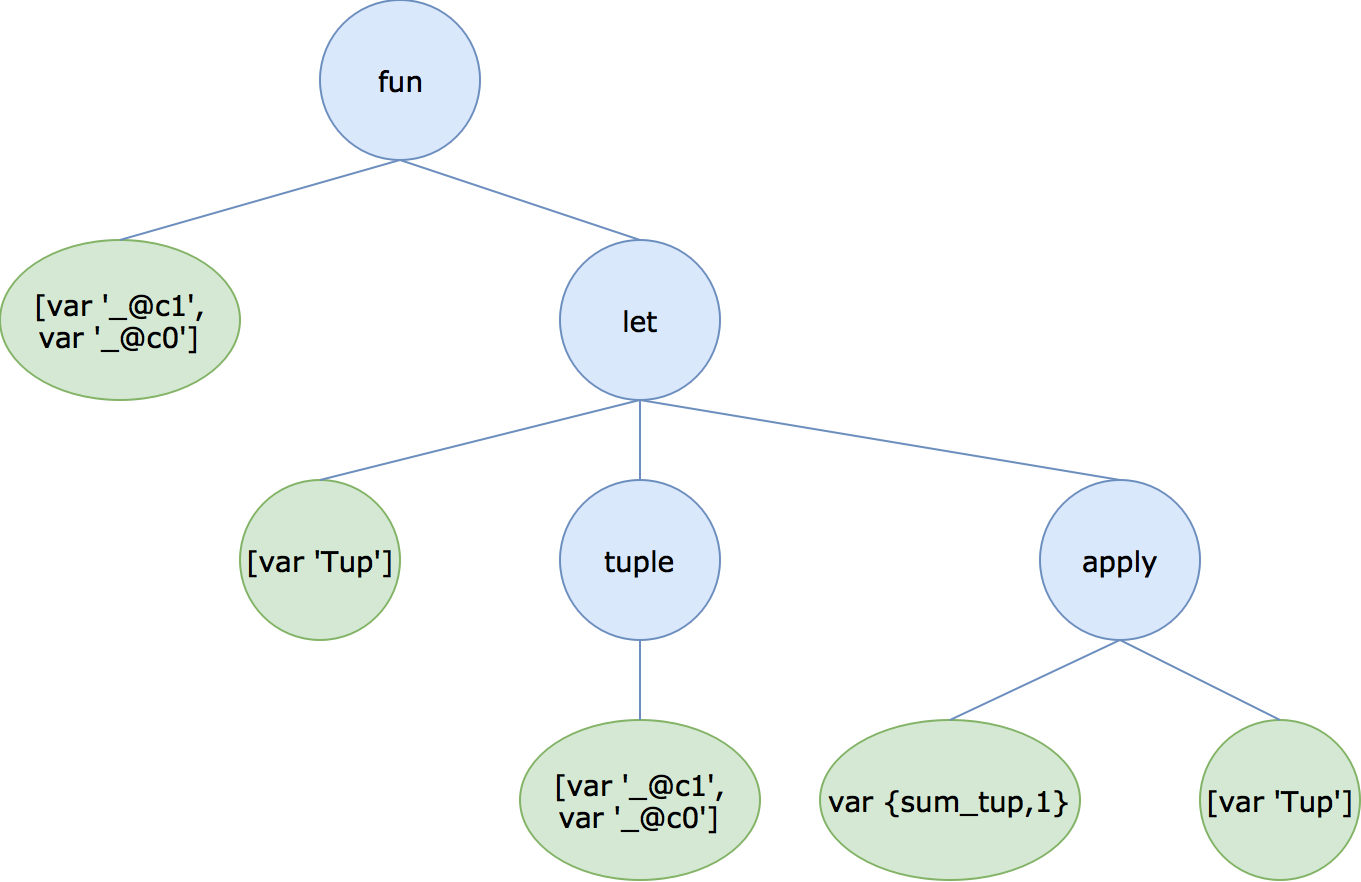
Here, the left child of the root node are the arguments of the function (a list
of variables), and the right subtree is the body of the function which, in turn,
is a let expression. The subtrees of a let expression are (from left to right)
variables, argument and body. In this let expression, Tup (the variable) will
be bound to a tuple {_@c1,_@c0} (the argument), so that the sum_tup(Tup)
application (the body) is evaluated with the inclusion of this binding.
Data Types
Since some constructs in Erlang can be considered syntactic sugar, these can be compiled into simpler ones when translated to Core Erlang. Thus, there are only a few Core Erlang AST data types. The main ones (and what they are used for) are:
-
'apply'for function applications. -
callfor function calls. -
'case'for case statements. -
clausefor clauses in case and receive statements. -
consfor list constructors. -
'fun'for function definitions. -
letfor let expressions. -
literalfor atoms, numbers, characters… -
modulefor module definitions. -
'receive'for receive statements. -
tuplefor tuples. -
varfor variables.
Note that this is not an exhaustive list of the Core Erlang AST data types.
Nevertheless, I consider these to be the most important, although the missing
ones (binary, catch, etc.) could also appear in your programs (i.e., it
depends on your problem).
The type of a node can be obtained with the cerl:type/1 function. Another
option is to match with the record type of a node directly (#c_apply{...},
#c_call{...}, etc.), but I prefer the former option because I think it is
easier to read, in general.
Core Erlang Metaprogramming in Erlang
In our case, the metaprogramming process can be divided into three steps:
- Translate Erlang source code to Core Erlang forms.
- Manipulate the Core Erlang forms.
- Generate Core Erlang code from forms.
These steps can be thought of as read, modify and write if you regard code and forms two representations of the same thing: A program. In addition, I will also describe a last step: Compiling the Core Erlang code (i.e., the code that we have written) to generate a BEAM file.
From Erlang code to Core Erlang forms
In the last part, we saw how to get the forms associated to the Core Erlang
code using the compile:file/2 function.
case compile:file(File, [to_core, binary, no_copt]) of
{ok, _, CoreForms} ->
CoreForms;
_ ->
io:fwrite("Error: Could not compile file.~n").
end.
We already know that the to_core option in the compile:file/2 call is used
to obtain the Core Erlang forms, but there are some other options that can be
useful here:
-
binary: By default,compile:filegenerates a file (the result of the compilation). With this option, we avoid its generation. -
no_copt: Disables compiler optimizations.
If we aim at generating a modified version of our program and we are not
interested in the unchanged version, then we should include the binary option.
Occasionally, the translated forms do not have a clear correspondence with the
original Erlang code (because of compiler optimizations). In these cases, you
can use no_copt to obtain forms that are closer to original code.
Manipulation of Core Erlang forms
Once you have read the forms, it is possible to perform the transformation node by node, starting by the module node, and propagating it to the subnodes. This way, you get full control over the transformations you perform on each node, and whether you propagate or not these transformations to their subtrees.
However, if your transformation is going to focus on a particular type of node,
I would recommend using the cerl_trees:map/2 function instead.
cerl_trees:map/2 receives a tree and a function, and it traverses the tree
applying this function to each node.
Suppose we have been asked to replace any appearance of the concatenation
operator (here, a call to the ++/2 function) by a list constructor (i.e.,
convert [X] ++ Xs to [X|Xs]) in some module. To solve this problem, we could
write:
replace_concat(Node) ->
case cerl:type(Node) of
call ->
ConcCallName = cerl:concrete(cerl:call_name(Node)),
case ConcCallName of
'++' ->
[FstArg, SndArg] = cerl:call_args(Node),
FlatFstArg = cerl:cons_hd(FstArg),
cerl:c_cons(FlatFstArg,
SndArg);
_ -> Node
end;
_ -> Node
end.
The replace_concat/1 function receives Node as the input and checks its
type. Then, if Node turns out to be a function call to ++, we return a new
constructor list node (created with cerl:c_cons(...)) where:
-
FlatFstArgis the flattened version of the first call argument. -
SndArgis the second call argument.
Otherwise, we return Node as it is. Thus, a call like [1] ++ [2,3] will be
replaced by [1|[2,3]] at the Core Erlang level. Note that we must flatten the
first argument, or otherwise we would obtain [[1]|[2,3]] instead, a different
result.
Therefore, we can use the cerl_trees:map/2 function to apply
replace_concat/1 to each node in the Core Erlang forms we have obtained from
the Erlang code (here, CoreForms):
TransForms = cerl_trees:map(fun replace_concat/1, CoreForms).
Clearly, this is just a simple example to illustrate how to manipulate Core Erlang forms, but we can think of more realistic examples: Program instrumentation (for tracing or profiling), pattern matching transformations (for program analysis or optimization), etc.
From Core Erlang forms to code
In this step, we simply must write the Core Erlang code associated to the
transformed forms into a file. Here, we can rely on the
cerl_prettypr:format/1 function for generating this code (a text string) from
the transformed forms:
file:write_file("transformed.core",
cerl_prettypr:format(TransForms)).
I have created a gist for this example (up to this step) so that you can replicate it on your computers.
From Core Erlang code to BEAM bytecode
Compiling a Core Erlang file works the same way as compiling an Erlang file,
with the difference that you must specify +from_core as an option when you run
the compiler:
erlc +from_core module.core
The same thing applies to compiling from the Erlang shell:
c('module.core', [from_core]).
Alternatively, you can use again the compile:file/2 function in your program
with the from_core option (and without the binary one) to compile the file
that you have just written, so that you automate every step in the
metaprogramming procedure.
Node annotations
Apart from the data type and the subtrees in a node, there is another field dedicated to annotations. By default, annotations contain the name of the file and the corresponding line in the Erlang source code.
Node annotations can be quite useful is some cases. For instance, if we have to perform an analysis in some Core Erlang code prior to a second pass algorithm, we can use annotations to store any data that could be useful during the second pass.
Other resources
I find that the most useful resources when working on Core Erlang metaprogramming are the Erlang docs for the compiler. Basically, these docs are the APIs for modules that we have already used (cerl, cerl_trees, etc.) and some others that can be useful in some cases (cerl_clauses, core_pp, etc.). However, most of the functions are not documented, and some testing is required in order to know what these do.
My colleague Salvador Tamarit, who has been working on Erlang for a long time now, prepared some slides (with examples) about metaprogramming in both Erlang and Core Erlang some years ago:
- Salvador Tamarit - Erlang: Types, Abstract Form & Core
- Salvador Tamarit - Metaprogramming for Erlang Abstract Format & Core
Finally, if you are interested in manipulating Erlang code instead,
smerl is a library that eases this
process. However, I am not aware of similar libraries for Core Erlang
metaprogramming. Perhaps I will write it at some point ![]()


